
Damit Suchmaschinen wie Google passende Ergebnisse zu einer Suchanfrage ausspielen können, bedarf es einer großen Datenbasis. Diese nennt man auch den Index einer Suchmaschine. Suchmaschinen durchforsten dabei das Internet und analysieren alle Seiten, die der Crawler findet, nach Inhalt und Relevanz. Standardmäßig werden dabei alle Seiten mit in den Index aufgenommen, wenn man nicht aktiv etwas dagegen unternimmt.
Als Webmaster oder Webseitenbetreiber stehen dir dafür 2 Möglichkeiten zur Verfügung, um bestimmte Seiten nicht im Index listen zu lassen oder auch diese nachträglich aus dem Index zu entfernen. Dafür lassen das „noindex-Tag“ oder die „robots.txt“ nutzen. In diesen Artikel erklären wir, was hinter diesen Begrifflichkeiten steht und wann welche Methode eingesetzt werden sollte. Am Ende kannst du dann hoffentlich selber die Seiten aus der Suche ausschließen, die du dafür vorgesehen hast.
Das noindex-Tag – Die richtigen Signale zur Deindexierung senden
Als Webseitenbetreiber oder SEO kannst du dem Crawler der Suchmaschine an verschiedenen Stellen Anweisungen erteilen, wie er die betroffene Seite lesen soll. Der bekannteste ist hierbei das „Robots-Tag”. Hierbei wird die grundlegendste Funktion des Crawlers definiert: Soll die Seite indexiert werden oder nicht?
Das Robots-Tag wird grundsätzlich in vier verschiedenen Varianten ausgegeben:
| Befehl | Funktion |
|---|---|
| „index, follow“ | Die Seite wird indexiert und alle vorhandenen Links werden weiter analysiert. |
| „index, nofollow“ | Die Seite wird indexiert, aber alle vorhandenen Links werden nicht weiter analysiert. |
| „noindex, follow“ | Die Seite wird nicht indexiert, aber alle vorhandenen Links werden weiter analysiert. |
| „noindex, nofollow“ | Die Seite wird nicht indexiert und alle vorhandenen Links werden nicht weiter analysiert. |
Damit nun eine Suchmaschine die Seite nicht in den Index, und somit ebenfalls nicht in den Suchergebnissen ausspielt, wird das Robots-Tag mit dem Befehl „noindex“ ausgestattet. Ob hierbei für den Crawler Schluss ist oder er die weiteren Links auf der Seite verfolgen soll, wird mit dem „follow“ bzw. „nofollow“ Befehl festgelegt. Normalerweise würde man wohl die „noindex, follow“ Variante wählen, damit der Crawler den Rest der eigenen Webseite normal weiter untersuchen kann.
Implementierung des noindex-Tags im Header
Das noindex-Tag kann, je nach technischer Umgebung, an zwei Stellen gesetzt werden. Die gebräuchliche und einfachste ist hierbei im Header einer Webseite.
Der Header ist der oberste Bereich im Quellcode einer Webseite. Hier werden grundsätzliche Dinge definiert, wie z.B. das Styling bzw. das Stylesheet einer Seite, die das Design bestimmt. Im Header wird aber auch das oben beschriebene Robots-Tag platziert.
Beispiel: Für eine deindexierte Seite mit Erlaubnis den Links zu folgen, wird das Robots-Tag wie folgt definiert:
<meta name=“robots“ content=“noindex,follow“ />
Dieser Codeschnipsel kann so direkt in den Quellcode integriert werden.
Solltet ihr WordPress verwenden gibt es passende Plugins, die euch unterstützen. Überhaupt ist das Thema WordPress SEO komplex und daher haben wir diesem Bereich einen eigenen Artikel gewidmet. Mit einem passenden Plugin wie z.B. Yoast könnt ihr aber schnell und einfach in den Einstellungen für jede Unterseite die Einstellung vornehmen.
Implementierung des noindex-Tags auf Serverseite als X-Robots-Tag
Als weitere Variante kann das Tag aber auch auf Serverseite implementiert werden. Diese Methode ist etwas aufwendiger, kann dafür aber auch für Nicht-HTML Seiten wie z. B. PDF Dateien verwendet werden. Hierbei spricht man von dem X-Robots-Tag.
Das X-Robots-Tag wird, je nach Server-Setup, in der sogenannten .htaccess Datei gesetzt und sendet dieselben Signale, die auch das Robots-Tag im Header sendet. Ebenfalls müssen vorher die Datei bzw. die Dateien definiert werden. Sollen zum Beispiel mit einem Apache Server alle PDF Dateien deindexiert werden, wird das X-Robots-Tag wie folgt definiert:
<Files ~ „\.pdf$“>
Header set X-Robots-Tag „noindex, nofollow“
</Files
robots.txt al Alternative – Suchmaschinen den Zugriff zu einzelnen Seiten oder Bereichen verweigern
Die robots.txt Datei ist eine einfache Textdatei, die auf dem Root einer Webseite, d. h. im obersten Verzeichnis, z. B. https://domain.tld/robots.txt liegt.
Hier werden ebenfalls verschiedene Signale an die Suchmaschinen gesendet. Im Folgenden liegt der Fokus auf Allow und Disallow. Oft gibt es Verzeichnisse auf dem Webserver, auf die Suchmaschinen keinen Zugriff haben sollen. In vielen Fällen handelt es sich hierbei um Admin-Verzeichnisse oder Serverdateien. Um nun Suchmaschinen den Zugriff auf eine bestimmte Datei oder ein Verzeichnis zu verbieten, wird das Attribut Disallow gesetzt.
Als Beispiel kann man hier eine Variante, in Verwendung des bekanntesten Content Management Systems (CMS) WordPress, nehmen:
User-agent: *
Disallow: /wp-admin/
In diesem Beispiel werden alle Crawlern angewiesen auf das Verzeichnis /wp-admin/ nicht zuzugreifen. So wird die Administrationsumgebung des CMS sozusagen vor den Crawlern geschützt.
Aber Vorsicht: Ein Eintrag in die robots.txt Datei verbietet den Zugriff auf eine Seite und kann schon bei kleinen Schreibfehlern bereits zu großen Problemen in der Sichtbarkeit führen. Falsch konfiguriert führt das vielleicht dazu, das ein ungewolltes Verzeichnis ebenfalls ausgeschlossen wird.

Wann sollte man das noindex-Tag und wann die robots.txt verwenden?
Die Deklaration über das noindex-Tag eignet sich dann, wenn Suchmaschinen die Seite bereits indexiert haben. Hiermit bekommt z. B. Google bei erneuter Analyse der Seite das Signal, die Seite aus dem Index zu entfernen. Dieses Vorgehen funktioniert normalerweise gut, braucht aber ein paar Tage oder Wochen bis Google die Anweisungen auch vollständig übernimmt.
Das Verbieten via robots.txt eignet sich dann, wenn die Seite noch nie indexiert wurde und auch zukünftig nicht indexiert werden soll. Oftmals werden diese Angaben beim Launch bzw. Relaunch einer Seite gesetzt. Auch hier kann es aber zu Problemen kommen. Wird das robots.txt-Tag bspw. bei einer bereits indexierten Seite eingesetzt, kann diese unter Umständen nicht aus dem Index entfernt werden, da der Crawler der komplette Zugriff auf die Seite verweigert wird. So kann der Crawler die Anweisung unter Umständen nicht auslesen.
Am besten nutzt ihr beide Varianten zusammen. Schließt Verzeichnisse komplett über die robots.txt aus, die wirklich nicht in den Index sollen. Für den Ausschluss von einzelnen Seiten nutzt ihr dann am besten das noindex-Tag. So können sich beide Varianten gut ergänzen und ihr behaltet die volle Kontrolle über eure Seite.
Google Tool zum Entfernen von URLs
Sofern du Zugriff auf die Search Console deiner Webseite hast, kannst du dort ein Tool zur Entfernung von URLs nutzen, mit dem die manuelle Entfernung einzelner URLs und Verzeichnisse beantragen werden kann. So kann bei neuen Anweisungen noch ein wenig nachgeholfen werden.
Dabei müsst du innerhalb des Tools, den kompletten Pfad der URL oder des Verzeichnisses angeben. Nach einem Klick auf “Weiter” hast du nun die Möglichkeit zwischen der vorübergehenden Ausblendung aus den Suchergebnissen (für ca. 90 Tage) oder der kompletten Entfernung aus dem Google Cache zu wählen.
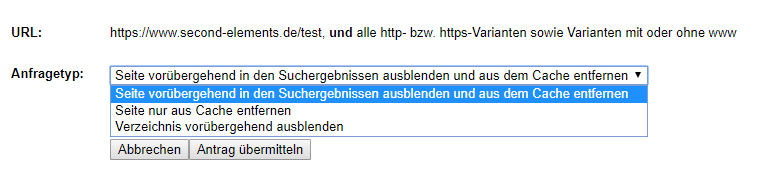
Die zweite Variante eignet sich besonders dann, wenn du wichtige Änderungen an der Website durchgeführt hast, da hier die alte Seite aus dem Zwischenspeicher des Google Indexes entfernt wird.
Achtung: Bei dieser Methode handelt es sich nur um eine kurzfristige Entfernung, bzw. Ausblendung aus den Suchergebnissen. Sollte die Seite weiterhin indexierbar und durch den Google Crawler auffindbar sein, wird diese auch wieder in den Google Index übernommen.
Nachträgliche Überprüfung der Entfernung
Solltest du mit Hilfe der oben genannten Methoden eine oder mehrere Seiten aus dem Google Index entfernt haben, gibt es eine einfache Methode, um diese zu überprüfen. Innerhalb der Google Search Console gibt es eine Funktion, mit der Sie eine Seite durch den Google Bot abrufen lassen können. Diese Funktion hilft dir dabei zu verstehen, wie Google die Seite sieht und darstellt. Damit lassen sich nicht nur grafische Fehler durch blockierte Elemente, sondern eben auch die Indexierung überprüfen.
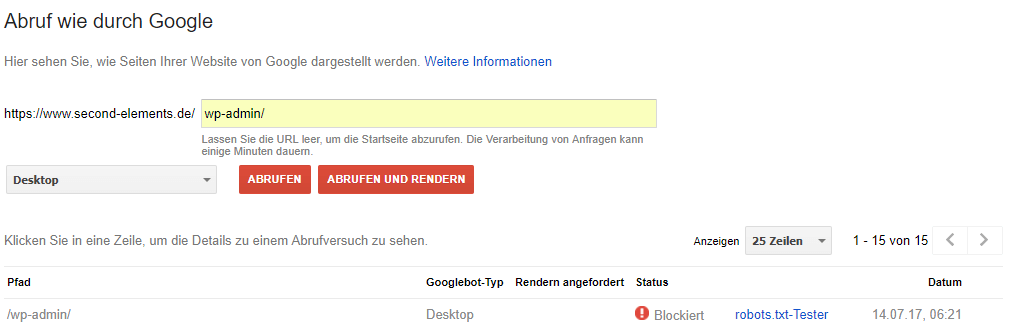
In diesem Screenshot sehen wir, dass das Verzeichnis “/wp-admin/” nicht von Google abrufbar und somit nicht indexierbar ist, da das Verzeichnis (zur Administration des CMS) innerhalb der robots.txt blockiert wurde.
Somit lässt sich einfach und schnell prüfen, ob Google die Seite in die Suchergebnisse aufnehmen kann oder nicht.
Fazit: Mit noindex UND robots.txt zum Erfolg
Suchmaschinen analysieren prinzipiell so viele Seiten wie möglich und wollen praktisch alles in den Index mit aufnehmen. Es gibt aber viele gute Gründe, warum einzelne Seiten oder ganze Verzeichnisse nicht in den Google Index gehören. Nach Möglichkeit sollten nur die relevanten Seiten für Google zur Verfügung gestellt werden. Das schont Googles Ressourcen und ermöglicht euch ein sauberes Indexmanagement. Bei richtiger Umsetzung zahlt das positiv auf eure Rankings ein.
Ans Ziel könnt ihr sowohl mit dem noindex-Tag als auch mit der robots.txt gelangen. Am besten funktionieren aber beide Möglichkeiten zusammen. Ihr müsst also nicht entweder oder wählen, sondern könnt auf UND setzen. Bei den Details kann es jedoch etwas schwierig werden, weshalb wir euch zu einem Testing-Tool oder einem SEO-Experten raten würden, wenn ihr hier aktiv werden wollt.